EECS 298: Social Consequences of Computing
Lab 10
Task
Your task in this lab is to use the unittest package to write a simple “model audit” for two given black box models. You will load the models and relevant data from Models.py and write and run six test cases in class in lab10.py.
Dataset and Models.py
First, use wget to download dataset.csv and Models.py.
wget https://raw.githubusercontent.com/eecs298/eecs298.github.io/main/files/dataset.csv
wget https://raw.githubusercontent.com/eecs298/eecs298.github.io/main/labs/Models.py
The dataset contained in dataset.csv is a toy example of a collection of some positive (\(y=1\)) and negative (\(y=-1\)) labeled points with two feature dimensions: \(x_1\) and \(x_2\). The dataset can be visualized below
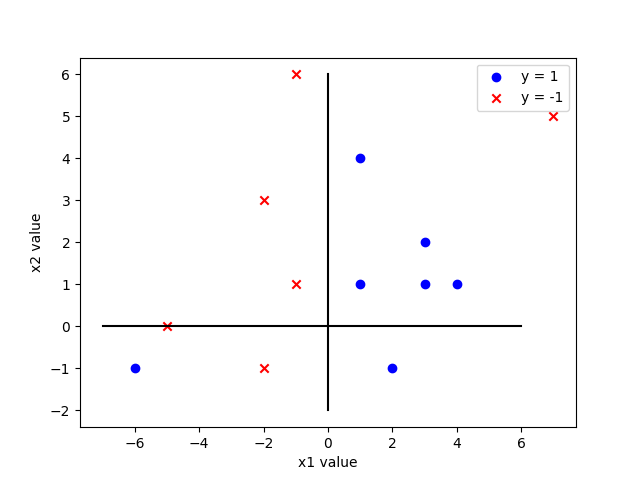
In Models.py, you will see a simple script that trains two models: model_1 and model_2. You will be able to import these variables to use test model in lab10.py.
lab10.py
Create a file called lab10.py in the same folder as dataset.csv and Models.py. We will also practice importing specific package versions using pip. Create a file named requirements.txt that contains the following versions of packages:
lime==0.2.0.1
numpy==1.24.2
scikit-learn==1.4.1.post1
numpy==1.24.2
Then, optionally activate a new virtual environment, and run the following command to make sure you are using the correct package verisons in this lab.
pip install -r requirments.txt
Imports
In lab10.py you will first import the following packages: lime, unittest,and sys. You will then import from Models the two models: model_1 and model_2 and the following data: training_x, testing_x, testing_y which are all numpy arrays. Since we are just importing a few variables from a local file, there is no need to create an empty __init__.py file as is necessary for treating directories as packages (see lab slides). When running lab10.py, you will notice a folder called __pycache__ get created and this is a result of storing the compiled version of Models.py when we import it so that Python does not need to rerun it each time we use a variable.
ModelAudit class
Next, in lab10.py you will create a class called ModelAudit that inherits from unittest.TestCase. This class will have six functions which correspond to the three tests you will run on each model. From the graph above, we see that the value of x1 is a much better indicator than the value of x2 as to whether the point should be positive or negative, so we first want to test that the lime explanations of each model for each test point weight the feature x1 higher than the feature x2. Next, we will test that each model is performing well by testing that the accuracy of each is at least 0.70. Finally, suppose we care about making sure positive points are classified correctly in our setting. Our last test will be to check that the true positive rate of each model is at least 0.80. Each test is further explained below. Note that you should have two functions for each test – one for each model (i.e., change model_XX to model_1 and model_2).
test_explanations_model_XX(self): This test will create alime_tabular.LimeTabularExplainerobject withtraining_data= training_x,feature_names=["x1", "x2"], anddiscretize_continuous=False. Use this explainer to runexplain_instanceon eachxintesting_xformodel_XX. Make sure to pass inmodel_XX.predict_probafor the prediction function argument inexplain_instancesincelimeworks with prediction probabilities. See the Tips below for how to access the feature weights from the output ofexplain_instance. This test will assert that for eachxintesting_x, the absolute value of the feature weight forx1is strictly greater than the feature weight forx2.- If the assertion for
model_XXat any test point fails, then add the messagef"FAILED: Model XX has an instance where the weight of x2 >= weight of x1"to the assertion to indicate the model number that failed and why it failed.
- If the assertion for
test_accuracy_model_XX(self): This test will assert thatmodel_XXhas an accuracy greater than or equal to0.70.- If the assertion for
model_XXfails, then add the messagef"FAILED: Model XX has accuracy {model_XX_accuracy:.5f}to the assertion to indicate the model number that failed and what its accuracy is (rounded to 5 decimals) so we can see why it failed.
- If the assertion for
test_TPR_model_XX(self): This test will assert thatmodel_XXhas a true positive rate greater than or equal to0.80.- If the assertion for
model_XXfails, then add the messagef"FAILED: Model XX has TPR {model_XX_tpr:.5f}"to the assertion to indicate the model number that failed and what its TPR is (rounded to 5 decimals) so we can see why it failed.
- If the assertion for
__main__ branch
Create a __main__ branch in lab10.py and add the following code to run the test cases you created and send the output to standard output:
test_models = unittest.TestLoader().loadTestsFromTestCase(ModelAudit)
unittest.TextTestRunner(stream=sys.stdout).run(test_models)
You will see an output that indicates there was one failure out of the 6 possible tests – model_1 does not assign high enough weight to the feature x1!
Turn in lab10.py to Gradescope when you are done.
Tips
Using unittest
The unittest package allows you to create classes of test suites for your code. The class you create will inherit from unittest.TestCase and each function in the class represents one test and will start with word test in the function name. The implementation in each function tests something using self.assertXX statements where XX can be statements like True, assertLess, etc. See all possible assert statements and more information on basic usage here. A simple class implementation to test the string class is given below (the example is from the above link). Note the code in the __main__ branch loads the test case and pipes it to standard output.
import unittest
class TestStringMethods(unittest.TestCase):
def test_upper(self):
self.assertEqual('foo'.upper(), 'FOO', msg="ERROR: upper case did not work") # The msg argument prints if the assertion fails
def test_isupper(self):
self.assertTrue('FOO'.isupper())
self.assertFalse('Foo'.isupper())
def test_split(self):
s = 'hello world'
self.assertEqual(s.split(), ['hello', 'world'])
# check that s.split fails when the separator is not a string
with self.assertRaises(TypeError):
s.split(2)
if __name__ == '__main__':
test_strings = unittest.TestLoader().loadTestsFromTestCase(TestStringMethods)
unittest.TextTestRunner(stream=sys.stdout).run(test_strings)
Using lime
The lime package contains the implementation of the lime explanations model. All possible uses can be found [here] (https://lime-ml.readthedocs.io/en/latest/lime.html#), but the example for using LimeTabularExplainer is given below since we use this explainer in this lab (we have tabular data).
from lime import lime_tabular
import numpy as np
from Models import model # importing some black box model from a local file names Models.py
training_data = np.array(SOME DATA)
explainer = lime_tabular.LimeTabularExplainer(training_data=training_data,feature_names=["feature1", "feature2"])
testing_data = np.array(SOME OTHER DATA)
for x_t in testing_data:
explanation_list = explainer.explain_instance(x_t, model.predict_proba).as_list()
print(explanation_list)
The output will look like
[('feature1', weight_feature_1), ('feature2', weight_feature_2)] # for test point 1 if feature 1 has a higher weight than feature 2.
[('feature2', weight_feature_2), ('feature1', weight_feature_1)] # for test point 2 if feature 2 has a higher weight than feature 1.
...
Note that the returned list outputs the feature names and weights for the explainer linear classifier in order of largest (absolute) weight to smallest.
Importing modules
When you import functions/variables/classes/etc. from a local python file, the local python file is called importing a module. Once a local file is imported into another file, it must be compiled once (ran with the output saved) and the compiled version of the file is stored in a folder called __pycache__. An example of importing a module is given below.
Say we have a file file.py that contains a function and a variable.
def a_function(*args):
# Do something
local_variable = 298
We can import file.py to another file in the same directory as follows
from file1 import a_function # import the function
from file1 import local_variable # import the variable
new_string = f"Welcome to EECS {local_variable}"
a_function(new_string)
Note that this is a simple example of just importing from one local file, but you can do more complicated importing and treat a directory like a package as well. For more information see here.